Redis
Remote Dictionary Server 即远程字典服务, 是一个开源的使用 ANSI C 语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value 数据库,并提供多种语言的 API, Redis 能读的速度是 11 万次/s,写的速度是 8.1 万次/s
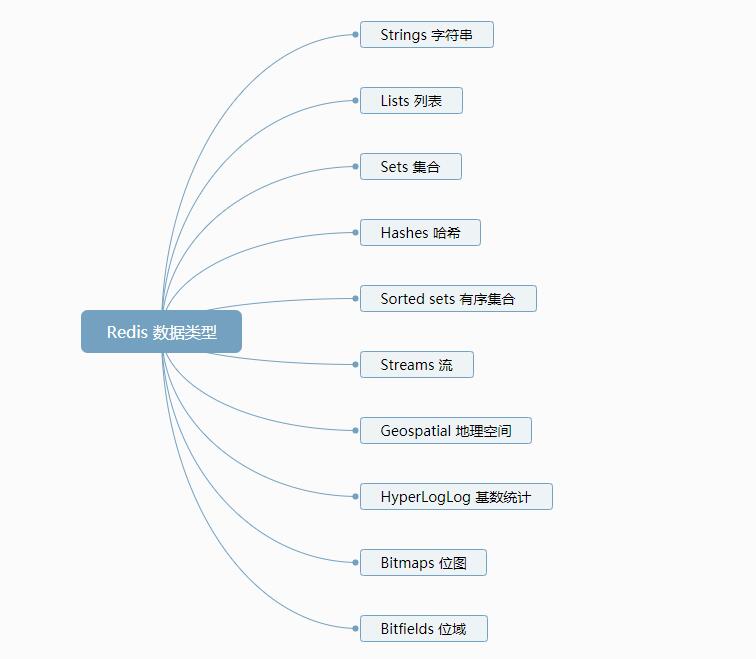
Redis 通常被称为数据结构服务器, 因为它的核心数据类型包括字符串、列表、字典(或哈希)、集合和排序集合等大多编程语言都支持的数据类型. 高版本版的 Redis 还添加了计算基数、地理定位和流处理等高级功能
数据类型
哈希标签
使用 哈希标签 方式操作 key, 无论 key 前后缀多长, Redis 只会对哈希标签内的值做 CRC16 计算, 相同值的 key 会分配到同一个槽, 保证 MGET/MSET/Lua 等操作的原子性
- “user:{1001}:profile”
- “order:{1001}:list”
- “cart:{1001}”
{} 内的内容决定槽位, 外面的值不参与计算
工具命令
- redis-benchmark 压测工具
- -h 主机名
- -p 端口号
- -s socket 连接(覆盖 host 和 port)
- -a 认证密码
- --user 用户名
- -c 客户端并发连接数(default 50)
- -n 请求数(default 100000)
- -d 测试数据的大小(default 3)
- --dbnum 连接的数据库编号(default 0)
- -k 是否保持连接
- -r SET/GET/INCR 使用随机 key, SADD 使用随机值
- -p 通过管道传输
- -q 退出, 仅显示 query/sec 值
- --csv 以 CSV 格式输出
- -l 循环永远运行测试
- -t 仅运行以逗号分割的命令列表
- -I Idle 模式, 仅打开 N 个 idle 连接并等待
- -x 从 STDIN 读取最后一个参数
1 | 127.0.0.1:6379>redis-benchmark -h localhost -p 6379 -c 100 -n 100000 -d 10 -t set,get,hset,hget,lpush,rpush,sadd |
redis-check-aof 检查 aof 备份文件
redis-check-rdb 检查 rdb 备份文件
redis-cli –user <username> –pass <password> 使用用户名密码连接 redis
-r 指定运行命令的次数
-i 设置不同命令调用之间的延迟(以秒为单位)
-x 从标准输入中读取最后一个参数
-n <db> 数据库编号
-t <timeout> 连接服务器的超时时间
--eval <file> 使用 EVAL 命令解析 lua 脚本
--function-rdb <filename> 从现有服务器中提取函数(不包含 key)
--scan 使用 SCAN 命令查找键
--bigkeys 查找大键
--pattern <pat> 当使用 –scan, –bigkeys, –memkeys, –keystats, –hotkeys 参数时, 匹配键的模式, 默认 *
--count <count> 当使用 –scan, –bigkeys, –memkeys, –keystats, –hotkeys 参数时, 匹配键的数量, 默认 10
--replica 设置主从关系的主节点
--stat 监控当前 redis 的使用情况
1 | # 加载 lua 脚本注册的 redis 函数 |
开机启动
- 创建
/usr/lib/systemd/system/redis.service服务文件, 使用yum install安装 Redis 自动创建此文件 - 编辑
redis.service文件
1 | [Unit] # 控制单元定义 |
- 使用命令
systemctl daemon-reload重启系统服务管理守护进程 - 使用命令
systemctl start redis.service启动 Redis 服务 - 使用命令
systemctl enable redis.service允许 Redis 服务开机启动
CONFIG 命令
CONFIG GET parameter [parameter…] 获取指定配置项的值
CONFIG HELP 显示 CONFIG 命令的帮助信息
CONFIG RESETSTAT 重置 INFO 返回的统计信息, ok 成功
CONFIG REWRITE 将内存中的配置项重写到配置文件中
CONFIG SET parameter value [parameter value …] 设置配置项
clear 清空屏幕
help command 显示命令的帮助信息
- @[string] 显示当前数据类型的帮助信息
ECHO message 打印信息
SAVE 保存数据到本地磁盘
WAIT numreplicas timeout 阻止当前客户端, 直到所有先前的写入命令成功传输并至少由指定数量的副本确认, 如果达到了以毫秒为单位指定的超时, 则即使尚未达到指定的副本数量, 该命令也会返回
ROLE 返回当前实例的角色是 master、slave、sentinel, 和当前实例上下文副本的信息
PING [message] 测试连接是否正常, 通常返回 PONG, 如果传入了 message 则会输出 message
QUIT 关闭退出当前连接
SHUTDOWN [NOSAVE|SAVE] [NOW] [FORCE] [ABORT] 同步保存数据到硬盘上并关闭服务
INFO [section [section …]] 返回服务的相关信息, 没有参数返回所有
server 返回 redis 服务的通用信息
clients 返回客户端链接的信息
1
2
3
4
5
6
7
8
9
10127.0.0.1:6379> INFO clients
# Clients
connected_clients:1
cluster_connections:0
maxclients:10000
client_recent_max_input_buffer:20480
client_recent_max_output_buffer:0
blocked_clients:0
tracking_clients:0
clients_in_timeout_table:0memory 返回内存的信息
persistence 返回持久化的信息 RDB 和 AOF
stats 返回统计信息
replication 返回副本的信息
1
2
3
4
5
6
7
8
9
10
11
12
13127.0.0.1:6379> INFO replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:5b0d7d50614d939be22b4bedb80450d13bfd64a0
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0cpu 返回 cpu 的信息
commandstats 返回命令统计信息
latencystats 返回命令延迟百分比统计信息
cluster 返回集群信息
modules 返回模块信息
keyspace 返回数据库相关统计信息
1
2# Keyspace
db0:keys=3,expires=0,avg_ttl=0errorstats 返回错误统计信息
all 返回所有信息(除了 modules)
default 返回默认配置信息
everything 返回所有信息(包含 all 和 modules)
CLIENT 管理客户端连接
- HELP 帮助命令
- ID 显示当前客户端连接的 ID
- INFO 显示当前客户端连接的基本信息
1
2
3
4127.0.0.1:6379> CLIENT ID
(integer) 7
127.0.0.1:6379> CLIENT INFO
id=7 addr=127.0.0.1:33676 laddr=127.0.0.1:6379 fd=13 name= age=1386 idle=0 flags=N db=0 sub=0 psub=0 ssub=0 multi=-1 watch=0 qbuf=26 qbuf-free=20448 argv-mem=10 multi-mem=0 rbs=1024 rbp=0 obl=0 oll=0 omem=0 tot-mem=22554 events=r cmd=client|info user=default redir=-1 resp=2 lib-name= lib-ver= io-thread=0 tot-net-in=1145 tot-net-out=265388 tot-cmds=41- LIST 显示所有客户端连接的信息
1
2
3127.0.0.1:6379> CLIENT LIST
id=7 addr=127.0.0.1:33676 laddr=127.0.0.1:6379 fd=13 name= age=1438 idle=0 flags=N db=0 sub=0 psub=0 ssub=0 multi=-1 watch=0 qbuf=26 qbuf-free=20448 argv-mem=10 multi-mem=0 rbs=1024 rbp=0 obl=0 oll=0 omem=0 tot-mem=22554 events=r cmd=client|list user=default redir=-1 resp=2 lib-name= lib-ver= io-thread=0 tot-net-in=1171 tot-net-out=265749 tot-cmds=42
id=12 addr=127.0.0.1:46842 laddr=127.0.0.1:6379 fd=14 name= age=183 idle=52 flags=O db=0 sub=0 psub=0 ssub=0 multi=-1 watch=0 qbuf=0 qbuf-free=0 argv-mem=0 multi-mem=0 rbs=1024 rbp=0 obl=0 oll=0 omem=0 tot-mem=2048 events=r cmd=monitor user=default redir=-1 resp=2 lib-name= lib-ver= io-thread=0 tot-net-in=69 tot-net-out=1223 tot-cmds=3- KILL 关闭指定客户端连接
- ADDR ip:port 关闭指定 IP 地址的客户端连接
- ID client-id 关闭指定 ID(CLIENT LIST) 的客户端连接
- TYPE type 关闭所有指定类型的客户端, normal, master, slave, replica, pubsub
- USER username 关闭所有使用用户名认证的客户端连接
- MAXAGE maxage 关闭所有超过指定使用时间(秒)的客户端连接
1
2127.0.0.1:6379> CLIENT KILL ID 12
(integer) 1- PAUSE timeout [WRITE | ALL] 挂起所有或写操作的客户端连接指定的时间(毫秒)
- UNPAUSE 恢复挂起的客户端连接
MONITOR 启动监听模式输出服务器执行的每条命令
1 | 127.0.0.1:6379> MONITOR |
Keys 命令
操作 key
TYPE key 返回指定 key 的类型, none 表示 key 不存在
EXISTS key [key …] 检查指定 key 是否存在, 1 存在, 0 不存在
DEL key [key…] 阻塞删除 key 并返回成功删除 key 的数量
UNLINK key [key …] 非阻塞从键空间中取消指定 key 的链接(在其他线程中执行实际的内存回收), 并返回成功取消 key 的数量, 如果 key 不存在则忽略
RENAME key newKey 修改 key 的名称, 如果指定 key 不存在返回 错误, 如果 newkey 已存在则覆盖
RENAMENX key newkey 修改 key 的名称, 如果指定 key 不存在返回 错误, 如果 newkey 已存在不执行任何操作返回 0, 否则返回 1
MOVE key db 将当前数据库中的 key 移动到指定的数据库(db)中
DUMP key 序列化指定 key, 并返回被序列化的值, 不存在返回 <nil>
TOUCH key [key …] 更改指定 key 的最后一次访问时间并返回修改成功的数量, 如果 key 不存在则忽略
SORT key [BY pattern] [LIMIT offset count] [GET pattern [GET pattern …]] [ASC|DESC] [ALPHA] [STORE destination]
对 list、set、zset 集合中的元素进行排序, 默认是按照数字或者元素的双精度浮点数去比较
KEYS pattern 查找给定模式(pattern)的 key, 返回列表, 未找到返回 (empty array),
KEYS *返回所有 key, 阻塞式全量扫描SCAN cursor [MATCH pattern] [COUNT count] [TYPE type] 查找给定模式(pattern)的 key, 返回列表和上次遍历时的游标, 非阻塞式扫描
- COUNT 控制匹配结果的数量, 默认为 10
- TYPE 过滤匹配结果中的类型, 可取值 string, list, set 等 redis 支持的数据类型
1 | 127.0.0.1:6379> KEYS * |
过期时间
设置过期时间
- EXPIRE key seconds [NX|XX|GT|LT] 为指定 key 设置过期时间(单位秒), 1 设置成功, 0 指定 key 不存在或者提供的参数跳过了操作
- EXPIREAT key unix-time-seconds [NX|XX|GT|LT] 为指定 key 设置过期使用 unix 时间戳, 1 设置成功, 0 指定 key 不存在或者提供的参数跳过了操作
- PEXPIRE key milliseconds [NX|XX|GT|LT] 为指定 key 设置过期时间(单位毫秒), 1 设置成功, 0 指定 key 不存在或者提供的参数跳过了操作
- PEXPIREAT key unix-time-milliseconds [NX|XX|GT|LT] 为指定 key 设置过期时间使用 unix 时间戳, 1 设置成功, 0 指定 key 不存在或者提供的参数跳过了操作
- EXPIRETIME key 返回指定 key 将过期的绝对 Unix 时间戳(以秒为单位), -1 表示 key 存在但没有过期时间, -2 表示 key 不存在, Redis 7.0 支持
- PEXPIRETIME key 返回指定 key 将过期的绝对 Unix 时间戳(以毫秒为单位), -1 表示 key 存在但没有过期时间, -2 表示 key 不存在, Redis 7.0 支持
- NX 以上命令该参数作用相同, 仅当指定 key 没有过期时间时
- XX 以上命令该参数作用相同, 仅当指定 key 存在过期时间时
- GT 以上命令该参数作用相同, 仅当新的过期时间大于当前的过期时间
- LT 以上命令该参数作用相同, 仅当新的过期时间小于当前的过期时间
获取过期时间
- TTL key 返回指定 key 以秒为单位剩余的生存时间
- PTTL key 返回指定 key 以毫秒为单位剩余的生存时间
- -1 key 存在但没有设置剩余生存时间
- -2 key 不存在
1 | 127.0.0.1:6379> TTL age |
取消过期时间
- PERSIST key 移除指定 key 的过期时间, key 将永久保持, 1 成功, 0 key 不存在或者未设置过期时间
数据库操作
- RANDOMKEY 从当前数据库随机返回一个 key, 如果当前数据库为空则返回 <nil>
- SWAPDB index1 index2 切换两个数据库
- SELECT index 更改当前连接的选定的数据库
- DBSIZE 返回当前数据库中 key 的数量
清空数据库
- FLUSHALL [ASYNC|SYNC] 清除所有数据库中的 key, 执行成功返回 ok
- FLUSHDB [ASYNC|SYNC] 清除当前数据库中的 key, 执行成功返回 ok
副本
- REPLICAOF host port 将当前服务器设置为指定主机端口上服务器的副本, 通常返回 ok, Redis 5.0 开始代替
SLAVEOF- 如果当前服务器已经是某个服务器的副本, 则取消对旧服务器的连接同步, 并开始对新服务器同步, 丢弃旧有数据集
- NO ONE 如果当前服务器已经是副本, 此参数将当前服务器变为 master, 并停止与主服务器的连接同步
安全认证
- AUTH [username] password 对当前连接的认证, 或者切换用户
配置文件配置项
include /path/to/*.conf # 导入其他 redis 配置文件
protected-mode yes # 保护模式, 默认 yes 只能允许本机连接
daemonize no # 后台运行模式
tcp-backlog 511 # tcp 连接数
timeout 0 # 关闭客户端连接的延迟, 0 表示禁用, 单位秒
tcp-keepalive 300 # 保持长连接的时间, 单位秒
TLS/SSL
安全连接配置项, 默认未开启
- tls-port 6379 # 安全连接端口
- tls-cert-file redis.cert # 安全连接证书
- tls-key-file redis.key # 安全连接 key
- tls-key-file-pass secret # key 文件加密摘要
- tls-client-cert-file client.crt # 客户端安全连接证书
- tls-client-key-file client.key # 客户端安全连接 key
- tls-client-key-file-pass secret # 客户端安全连接 key 文件加密摘要
- tls-ca-cert-file ca.crt # CA 证书
- tls-ca-cert-dir /etc/ssl/certs # CA 证书目录
- tls-auth-clients no # no 不需要也不接受客户端证书连接, optional 证书不必需, 如果提供证书则必须验证有效
- tls-session-caching no # 默认启用 TLS 会话缓存, no 表示禁用缓存
- tls-session-cache-size 5000 # TLS 缓存大小, 默认 20480
- tls-session-cache-timeout 60 # TLS 缓存有效期, 默认 300 秒
通用设置
loglevel notice # 设置日志级别, 默认 notice
- debug (a lot of information, useful for development/testing)
- verbose (many rarely useful info, but not a mess like the debug level)
- notice (moderately verbose, what you want in production probably)
- warning (only very important / critical messages are logged)
syslog-enabled no # 是否允许指向 系统 日志
syslog-ident redis # 日志标识符
databases 16 # 默认数据库数量
always-show-logo no # 是否总是显示 logo
set-proc-title yes # 设置进程标题
MEMORY
- maxmemory-policy noeviction # 内存管理策略
- volatile-lru 使用 LRU 算法移除 key, 只对设置了过期时间的 key
- allkeys-lru 在所有集合 key 中, 使用 LRU 算法移除 key
- volatile-lfu 使用 LFU 算法移除 key, 只对设置了过期时间的 key
- allkeys-lfu 在所有集合 key 中, 使用 LFU 算法移除 key
- volatile-random 在过期集合 key 中, 移除随机的 key, 只对设置了过期时间的 key
- allkeys-random 在所有集合 key 中, 移除随机的 key
- volatile-ttl 移除那些 TTL 值最小的 key, 即那些最近要过期的 key
- noeviction 不进行移除, 针对写操作, 只是返回错误信息
- maxmemory-samples 5 # 设置 Redis 移除 key 时的样本数量, 10 接近 LRU 算法但非常消耗内存, 3 最快却不是精确的
SNAPSHOTTING
- save 3600 1 300 100 60 10000 # 快照执行机制, 3600 秒后如果超过 1 次更改, 300 秒后超过 100 次更改, 60 秒后超过 10000 次更改
1 | save <seconds> <changes> [<seconds> <changes> ...] |
- stop-writes-on-bgsave-error yes # 是否开启停止在保存快照发生错误的时的写操作
- rdbcompression yes # 开启 rdb 文件压缩
- rdbchecksum yes # 开启 rdb 文件的校验检查
SECURITY
- acllog-max-len 128 # ACL 日志在内存中时的最大条目数
- aclfile /etc/redis/users.acl # 默认 ACL 配置文件
- io-threads 4 # I/O 线程
Redis Pipelining
当客户端使用流水线发送命令时, 服务器将被迫使用内存对回复进行排队. 因此, 如果需要使用流水线发送大量命令时最好尽量等分分批发送命令
Redis 流水线是一种通过一次发出多个命令而无需等待每个命令的响应来提高性能的技术, 大多数 Redis 客户端都支持流水线.
1 | # 使用 netcat 命令测试 |
ACL
Redis 6.0 支持
ACL(access control list)访问控制列表的简称, 是为了控制某些 Redis 客户端在访问 Redis 服务器时, 能够执行的命令和能够获取的 key, 提高操作安全性, 避免对数据造成损坏
- ACL HELP 显示 ACL 的帮助信息
1 | 127.0.0.1:6379> ACL HELP |
规则分类
| 参数 | 说明 |
|---|---|
| on | 启用用户, 默认为 off |
| off | 禁用用户 |
| +<command> | 将命令添加到用户可以调用的命令列表中 |
| -<command> | 将命令从用户可以调用的命令列表中移除 |
| +<command>|subcmd | 允许使用已禁用命令的特定子命令 |
| +@<category> | 允许用户调用 category 类别中的所有命令, 可以使用 ACL CAT 命令查看所有类别 |
| -@<category> | 禁止用户调用 category 类别中的所有命令 |
| allcommands | +@all 的别名 |
| nocommands | -@all 的别名 |
| ~<pattern> | 允许用户可以访问的 key(正则匹配), 例如: ~foo:* 只允许访问 foo:* 的 key |
| %R~<pattern> | 添加指定的只读 key(正则匹配), 例如: %R~app:* 只允许读 app:* 的 key, Redis 7.0 支持 |
| %W~<pattern> | 添加指定的只写 key(正则匹配), 例如: %W~app:* 只允许写 app:* 的 key, Redis 7.0 支持 |
| %RW~<pattern> | 添加指定的可读可写的 key(正则匹配), 例如: %RW~app:* 只允许读写 app:* 的 key, Redis 7.0 支持 |
| allkeys | ~* 的别名 |
| resetkeys | 移除所有的 key 匹配模式 |
| &<pattern> | 允许用户可使用的 Pub/Sub 通道(正则匹配) |
| allchannels | &* 的别名 |
| resetchannels | 移除所有的通道匹配模式 |
| ><password> | 为用户添加明文密码, 服务器自动转换成 hash 存储, 例如: >123456 |
| <<password> | 从有效密码列表中删除密码 |
| #<hash> | 为用户添加 hash 密码, 例如: #cab3…c4f2 |
| !<hash> | 从有效密码列表中删除密码 |
| nopass | 删除所有与用户关联的密码 |
| resetpass | 刷新密码列表并删除 nopass 状态 |
- ACL CAT 显示 Redis 的所有分类
1 | 127.0.0.1:6379> ACL CAT |
- ACL USERS 列出所有已配置用户名
- ACL WHOAMI 返回当前连接服务器的用户名, 默认 default
1 | 127.0.0.1:6379> ACL WHOAMI |
ACL SAVE 将 ACLs 配置项从内存保存到 ACL 文件中
ACL DELUSER [username…] 删除指定的 ACL 用户, default 用户不能被删除
ACL SETUSER 设置用户访问权限
ACL GETUSER username 获取指定用户的权限
1 | # 添加 lisi 账号, 明文密码 123456, 添加所有分类的命令 |
- ACL LIST 显示 Redis 服务器当前活动的 ACL 规则
1 | 127.0.0.1:6379> ACL LIST |
- ACL DRYRUN username command [arg [arg …]] 模拟指定用户对给定命令的执行, 此命令可以用来测试用户的权限而无需启用用户, Redis 7.0 支持
1 | 127.0.0.1:6379> ACL DRYRUN zhangsan ZADD zs 1 hello 2 world 3 zs |
事务
=== Redis 单条命令是保证原子性的, 但是 Redis 事务不保证原子性 ===
=== Redis 事务没有隔离级别的概念 ===
所有的命令在事务中, 并没有被执行而是加入队列, 只有发起执行命令的时候才会执行! EXEC
Redis 事务允许在一个步骤中执行一组命令, 事务中的所有命令都是串行化的, 并按顺序执行. 在 Redis 事务执行过程中, 另一个客户端发送的请求将永远不会被处理. 这保证了命令作为一个单独的操作执行
Redis 事务执行的三个重要保证:
- 批量操作在发送 EXEC 命令前被放入队列缓存
- 收到 EXEC 命令后进入事务执行, 事务中任意命令执行失败, 其余的命令依然被执行
- 事务执行过程, 其他客户端提交的命令请求不会插入到事务执行命令序列中
事务开始到执行的三个阶段
- 开启事务(multi): 使用
MULTI命令标记从非事务状态切换到事务状态 - 命令入队: 命令不会被立即执行, 而是被放入一个事务队列
- 执行事务(exec)或丢弃(discard)
事务命令
MULTI 标记一个事务块的开启, 通常返回 ok
EXEC 执行事务, 通常返回 ok
- 必须在
MULTI命令之后才能调用, 否则报错 ERR EXEC without MULTI - 如果
WATCH观察的 key 在当前的事务执行时已被修改, 则返回 <nil>
- 必须在
DISCARD 丢弃事务, 通常返回 ok
- 必须在
MULTI命令之后才能调用, 否则报错 ERR DISCARD without MULTI
- 必须在
WATCH key [key …] 监视一个或多个 key, 如果在事务执行之前观察的 key 被修改, 则事务将被打断, 通常返回 ok
- 如果在
MULTI命令后调用, 则会报错 ERR WATCH inside MULTI is not allowed
- 如果在
UNWATCH 取消所有观察的 key, 通常返回 ok, 如果调用了
EXEC或DISCARD命令, 通常不再需要调用此命令
1 | 127.0.0.1:6379> GET money |
编译时错误
1 | 127.0.0.1:6379> SET key1 hello |
运行时错误
1 | 127.0.0.1:6379> MULTI # 开启事务 |
不支持回滚
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现), 或是命令用在了错误类型的键上: 从实用性的角度来说, 失败的命令是由编程错误造成的, 而这些错误应该在开发环境中被发现, 不应该出现在生产环境中
- 因为不需要对回滚进行支持, 所有 Redis 的内部可以保持简单且快速
持久化
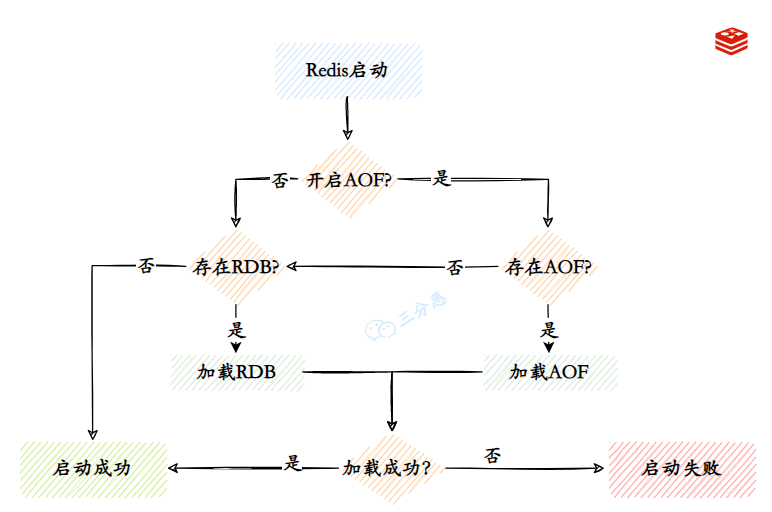
Redis 是基于内存的数据库, 遇到断电就会丢失数据, 持久化就是将内存中的数据保存到磁盘中便于以后使用, Redis 提供了 RDB 和 AOF 两种持久化方式, 默认使用 RDB 方式持久化数据
Redis 在持久化的过程中, 会先将数据写入到一个临时的文件中, 待持久化过程结束后, 才会用这个临时文件替换赏赐持久化生成的文件
触发方式
通过
FLUSHALL/FLUSHDB命令主动触发通过
SAVE/BGSAVE命令主动触发通过配置文件定期触发持久化操作
1 | # redis 7.0 写法 |
RDB
RDB(Redis Database), 在指定的时间间隔以指定的次数将内存中的数据集以快照的方式写入一个二进制文件中, 然后保存到磁盘中, 也就是 snapshot 快照, 默认生成的文件为 dump.rdb
Redis 会单独 fork 一个子进程进行持久化, 而主进程不会进行任何 I/O 操作, 这样就保证了 Redis 极高的性能, 如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是非常敏感, 此方式比 AOF 方式更加的高效
dbfilename dump.rdb默认 rdb 文件名dir ""工作目录, dbfilename, logfile, appenddirname 目录相对于当前配置项redis-check-rdb 检查 RDB 文件
RDB 优点
- 每隔一段时间完全备份一次
- 容灾简单, 可远程传输
- RDB 最大限度地提高了 Redis 的性能
- 文件较大时重启和恢复速度要快
RDB 缺点
- 如果备份时间间隔过长, RDB 会丢失较多的数据, 无法处理实时备份
- RDB 需要经常 fork() 以便使用子进程在磁盘上持久化, 增加 CPU 的负担
AOF
===如果 appendonly.aof 文件有错误, Redis 服务将会启动失败===
- redis-check-aof 检查 AOF 文件, --fix 参数修复文件的错误, 通常会丢弃文件中无法识别的命令
AOF(Append Only File), 将执行过的写命令全部记录下来, 在数据恢复时按照从前往后的顺序再将指令都执行一遍
appendonly yes启动 AOF 模式, 默认为 noappendfilename "appendonly.aof"默认文件名appenddirname "appendonlydir"默认存储目录, 相对于dir配置项appendfsync everysec持久化策略, 每秒钟执行一次, 可以修改为always和noalways每次将新命令附加到 AOF 时, 速度慢, 但是最安全no将写入策略权交给操作系统, 速度快, 但是不安全
no-appendfsync-on-rewrite noAOF 重写期间是否同步, 默认 no
Redis 7.0 支持使用新的 AOF 持久化方式, 包含三个文件, 当触发重写机制时, 自动创建新的基础文件和增量文件
- 以 appendfilename 为前缀命名的基础文件
appendfilename.*.base.rdb, 基础文件可以是 RDB 或 AOF - 以 appendfilename 为前缀命名的增量文件
appendfilename.*.incr.aof, 包含在上一个文件之后应用于数据集的其他命令 - 以 appendfilename 为前缀命名的清单文件
appendfilename.aof.manifest, 用于追踪文件及其创建和应用的顺序
如果同时开始 RDB 和 AOF 持久化时, Redis 重启时只会加载 AOF 文件, 不会加载 RDB 文件
AOF 优点
- AOF 更耐用, 可以在几秒钟内完成备份
- 当数据过大时, Redis 可以在后台自动重写 AOF, 节省空间
- AOF 实时性更好, 丢失数据更少, 并且支持配置写入策略
AOF 缺点
- 对于相同的数据集合, AOF 文件通常会比 RDB 文件大
- 在特定的 fsync 策略下, AOF 会比 RDB 略慢
- AOF 恢复速度比 RDB 慢
重写机制
auto-aof-rewrite-percentage 100AOF 重写的基准值, 当达到 100% 时重写auto-aof-rewrite-min-size 64mb当文件大小达到 64mb 的 100% 时重写BGREWRITEAOF 命令将会在后台开启 AOF 文件重写进程, 创建一个当前 AOF 文件的更小的优化版本, 如果重写失败不会丢失任何数据, 旧的 AOF 文件也不会受到影响
RDB 和 AOF 组合
fork 出的子进程先将共享的内存副本全量的以 RDB 格式写入 AOF 文件, 然后将 aof_rewrite_buf 重写缓冲区的增量命令以 AOF 格式写入到文件(在 RDB 格式数据的后面追加),
写入完成后通知主进程更新统计信息, 并将新的含有 RDB 格式和 AOF 格式的 AOF 文件替换旧的 AOF 文件. 新的 AOF 文件前半段是 RDB 格式的全量数据后半段是 AOF 格式的增量数据.
aof-use-rdb-preamble yes是否开始混合模式, 默认 yesRDB 做全量持久化
AOF 做增量持久化