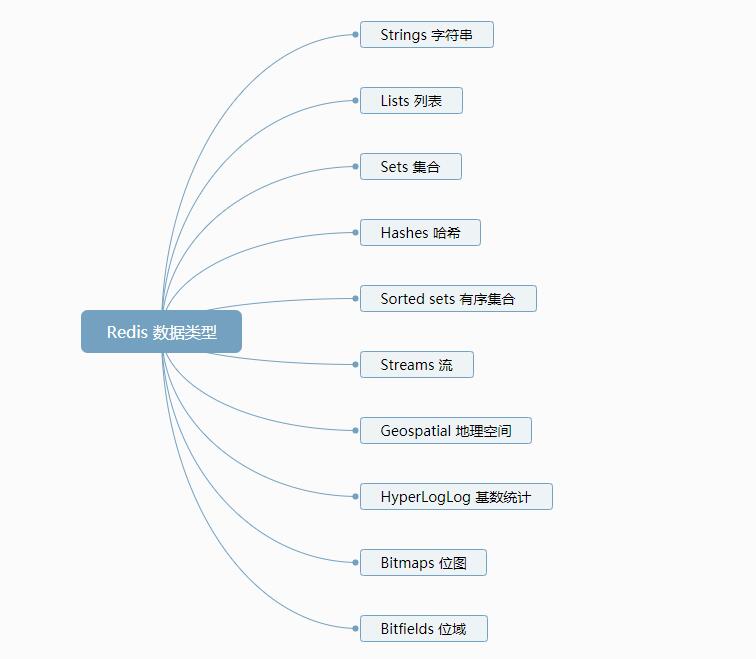
Strings 命令
字符串是基础的 key-value 类型, 存储字节序列, 包括文本、序列化对象和二进制数组, 一个 key 对应一个 value, value 可以是字符串、整数或浮点数, value 最多可以是 512MB.
String 类型的底层的数据结构实现主要是 int 和 SDS(Simple Dynamic String)
因为 C 语言的字符串并不记录自身长度, 所以获取长度的复杂度为 O(n), SDS 结构里用 len 属性记录字符串长度, 所有复杂度为 O(1)
设置值
SET key value [NX|XX] [GET] [EX seconds|PX milliseconds|EXAT unix-time-seconds|PXAT unix-time-milliseconds|KEEPTTL]
为 key 设置字符串的值, 执行成功返回 ok, 每次更新 key 的值时会自动清除过期时间
- NX 仅当 key 不存在时设置
- XX 仅当 key 存在时设置
- EX 过期时间, 单位秒
- PX 过期时间, 单位毫秒
- EXAT 过期时间戳, 单位秒
- PXAT 过期时间戳, 单位毫秒
- KEEPTTL 保留 key 关联的生存时间
1 | 127.0.0.1:6379> SET age 18 |
- SETNX key value 当 key 不存在时设置指定 key 的值, 返回值 1 成功, 0 失败
1 | 127.0.0.1:6379> KEYS * |
- APPEND key value 在指定 key 末尾(如果为字符串)追加内容, key 不存在同
SET并返回追加内容的长度
1 | 127.0.0.1:6379> APPEND age 1 |
过期时间
- SETEX key seconds value 设置 key 的值并设置过期时间(单位秒), 返回 ok
- PSETEX key milliseconds value 设置 key 的值的值并设置过期时间(单位毫秒), 返回 ok
1 | 127.0.0.1:6379> SETEX addr 20 beijing |
批量设置值
- MSET key value [key value …] 批量设置 key 的值
- MSETNX key value [key value …] 批量设置 key 的值且当所有的 key 不存在时, 返回值 1 成功, 0 失败
1 | 127.0.0.1:6379> KEYS * |
SETRANGE key offset value
覆盖指定 key 的从指定偏移量开始的字符串的一部分, 返回修改后字符串长度, key 不存在则新建
1 | 127.0.0.1:6379> SETRANG name 1 xyz |